Установка Ollama: локальный ИИ у себя на компьютере
Следующий шаг
Открой бота или продолжай маршрут внутри раздела.
Статья -> план в ИИ
Отправь ссылку на эту статью в любой ИИ и получи план внедрения под свой проект.
Прочитай эту статью: https://vibecode.morecil.ru/ru/rabochee-mesto/%D1%83%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BA%D0%B0-ollama-%D0%BB%D0%BE%D0%BA%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9-%D0%B8%D0%B8-%D1%83-%D1%81%D0%B5%D0%B1%D1%8F-%D0%BD%D0%B0-%D0%BA%D0%BE%D0%BC%D0%BF%D1%8C%D1%8E%D1%82%D0%B5%D1%80%D0%B5/
Работай в контексте моего текущего проекта.
Сделай план внедрения под мой стек:
1) что изменить
2) в каких файлах
3) риски и типичные ошибки
4) как проверить, что всё работает
Если есть варианты, дай "быстрый" и "production-ready". Как использовать
- Скопируй этот промпт и отправь в чат с ИИ.
- Прикрепи проект или открой папку репозитория в ИИ-инструменте.
- Попроси изменения по файлам, риски и короткий чеклист проверки.
Коротко: Ollama — это способ запускать большие языковые модели (LLM) у себя на компьютере. Не в браузере, не в облаке и не через чужие сервера. Модель живёт рядом с твоим кодом и файлами. Это фундамент для проектов, где важен контроль, конфиденциальность и независимость от внешних сервисов.
Зачем нужен локальный ИИ в разработке
Работая с облачным ИИ, ты всегда зависишь от провайдера. Сервис может изменить тарифы, ограничить API, перегрузиться или просто оказаться недоступным.
Локальный ИИ меняет парадигму:
- Контроль: Модель работает на твоём железе. Ты сам решаешь, когда и как её использовать.
- Конфиденциальность: Исходный код и данные не покидают твой компьютер.
- Независимость: Работа продолжается даже без подключения к интернету.
В вайбкодинге это не просто вопрос приватности, а вопрос архитектуры рабочего процесса. Ты строишь среду, где ИИ — это интегральная и предсказуемая часть твоего инструментария.
Что такое Ollama
Ollama — это не просто программа, а локальный рантайм и менеджер для ИИ-моделей.
Представь его как Docker для машинного обучения:
- Скачивает модели (как образы контейнеров) из публичных репозиториев.
- Управляет ими на твоём компьютере.
- Предоставляет простой API для взаимодействия.
Ключевой момент: Ollama сам не генерирует тексты. Он — среда исполнения. Качество и тип ответов полностью зависят от выбранной модели.
Почему именно Ollama
Для старта Ollama — идеальный выбор:
- Простота: Установка в несколько кликов, без глубоких знаний ML.
- Кроссплатформенность: Работает на macOS, Windows и Linux.
- Самостоятельность: Не требует аккаунтов, ключей API или платежей.
- Интегрируемость: Имеет простой API, что делает его идеальным для подключения к редакторам кода и другим инструментам.
Мы снова фиксируем мысль: ты выбираешь не «самую мощную» платформу, а самую практичную и понятнуюдля интеграции в свой рабочий поток.
Шаг 1: Установка Ollama
Процесс унифицирован для всех ОС.
Перейди на официальный сайт:
Нажми кнопку Download.
Скачай установщик для своей операционной системы:
.exeдля Windows,.dmgдля macOS,.debили.rpmдля LinuxЗапусти установщик. Следуй стандартным инструкциям установки, не снимая галочки по умолчанию (если не понимаешь, для чего они)
Важно: После установки Ollama запустится как фоновый сервис (демон). Тебе не нужно каждый раз открывать его как отдельное приложение. Он будет работать «в системном трее» и ждать твоих команд.
На Windows и macOS также установится Ollama в виде обычного приложения, которое можно открыть для простого чат-интерфейса.
Шаг 2: Проверка установки и первая команда
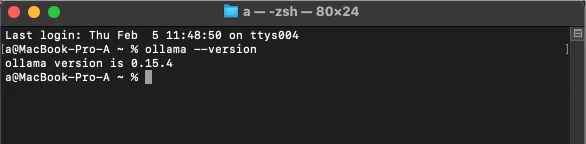
Открой терминал (Command Prompt, PowerShell, Terminal, iTerm2 и т.д.) и выполни команду:
ollama --version
В ответ ты должен увидеть номер версии, например,
ollama version 0.***
Это подтверждает, что Ollama установлен корректно и доступен из командной строки.
Шаг 3: Твоя первая локальная модель
Ollama без модели — это пустой контейнер. Давай скачаем и запустим нашу первую модель. Отличной отправной точкой является llama3.2, так как она современна, эффективна и хорошо работает на большинстве hardware.
В том же терминале выполни:
ollama pull llama3.2Что происходит:
- Ollama обращается к своему репозиторию (Model Library).
- Скачивает модель
llama3.2и все её зависимости на твой компьютер. - Процесс может занять несколько минут в зависимости от скорости интернета и размера модели (обычно несколько гигабайт).
После завершения загрузки модель готова к использованию.
Шаг 4: Базовое использование: интерфейс командной строки (CLI)
Самый простой способ пообщаться с моделью — это запустить её в интерактивном режиме.
ollama run llama3.2После выполнения команды ты увидишь приглашение >>>. Это значит, что модель загружена в память и готова к диалогу. Напиши любой вопрос или запрос и нажми Enter.
Пример:
>>> Напиши приветствие для нового проекта под названием "VibeCode"Чтобы выйти из интерактивного режима, введи /bye или нажми Ctrl+D.
Шаг 5: Интеграция с IDE и редакторами кода
Настоящая сила Ollama раскрывается при интеграции прямо в среду разработки. Вот основные способы:
1. Плагины и расширения
Многие популярные редакторы имеют плагины, которые подключаются к локальному серверу Ollama.
- VS Code: Установи расширение, например,
genaiилиcontinue. В настройках расширения укажите endpointhttp://localhost:11434 - Cursor: Идеально заточен под работу с ИИ. В настройках (Settings > AI Models) выбери "Ollama" и укажи модель (например,
llama3.2). Cursor будет автоматически отправлять запросы к твоему локальному Ollama. - JetBrains IDE (IntelliJ, PyCharm, etc.): Ищи плагины типа
CodeGeeXилиContinue, поддерживающие локальные модели через Ollama.
2. Напрямую через API
Ollama запускает локальный сервер на порту 11434. Ты можешь отправлять ему HTTP-запросы из своих скриптов или инструментов.
Пример простого запроса через curl:
curl -X POST http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt": "Объясни, что такое Python-декоратор",
"stream": false
}'Это открывает возможности для создания собственных инструментов автоматизации.
Что важно понять на этом этапе
Ты не просто «поставил программу». Ты добавил новый, управляемый слой в свою рабочую экосистему.
Теперь у тебя есть:
- Редактор кода.
- Твой проект.
- Локально работающий ИИ-ассистент, который понимает контекст твоего проекта и готов помочь, не требуя выхода в интернет.